# Diffusion Policy Policy Optimization (DPPO)
[[Paper](https://arxiv.org/abs/2409.00588)] [[Website](https://diffusion-ppo.github.io/)]
[Allen Z. Ren](https://allenzren.github.io/)1, [Justin Lidard](https://jlidard.github.io/)1, [Lars L. Ankile](https://ankile.com/)2,3, [Anthony Simeonov](https://anthonysimeonov.github.io/)3
[Pulkit Agrawal](https://people.csail.mit.edu/pulkitag/)3, [Anirudha Majumdar](https://mae.princeton.edu/people/faculty/majumdar)1, [Benjamin Burchfiel](http://www.benburchfiel.com/)4, [Hongkai Dai](https://hongkai-dai.github.io/)4, [Max Simchowitz](https://msimchowitz.github.io/)3,5
1Princeton University, 2Harvard University, 3Masschusetts Institute of Technology
4Toyota Research Institute, 5Carnegie Mellon University
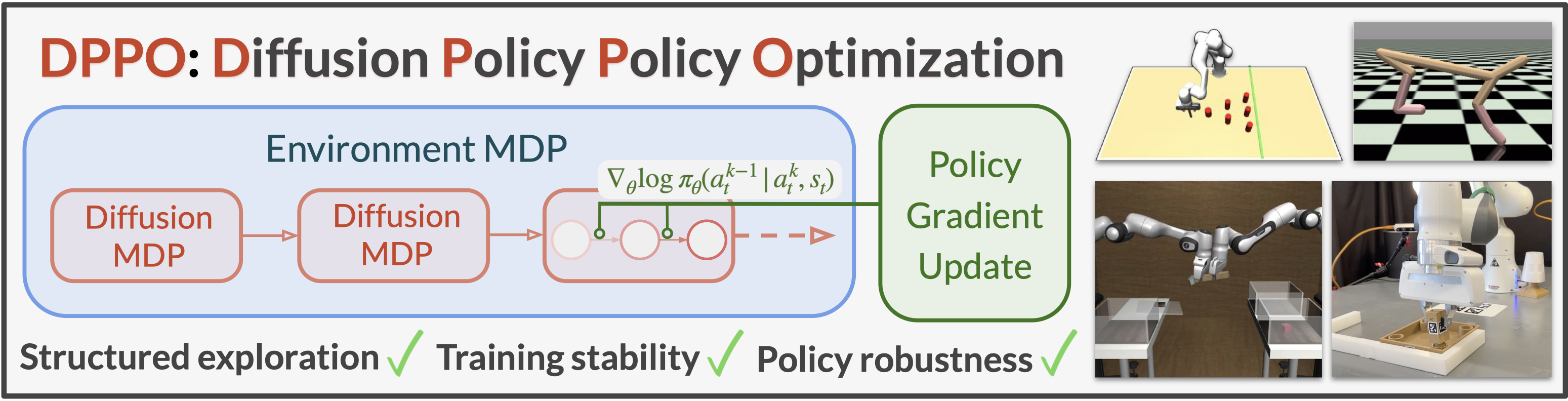 > DPPO is an algorithmic framework and set of best practices for fine-tuning diffusion-based policies in continuous control and robot learning tasks.
## Installation
1. Clone the repository
```console
git clone git@github.com:irom-lab/dppo.git
cd dppo
```
2. Install core dependencies with a conda environment (if you do not plan to use Furniture-Bench, a higher Python version such as 3.10 can be installed instead) on a Linux machine with a Nvidia GPU.
```console
conda create -n dppo python=3.8 -y
conda activate dppo
pip install -e .
```
3. Install specific environment dependencies (Gym / Kitchen / Robomimic / D3IL / Furniture-Bench) or all dependencies (except for Kitchen, which has dependency conflicts with other tasks).
```console
pip install -e .[gym] # or [kitchen], [robomimic], [d3il], [furniture]
pip install -e .[all] # except for Kitchen
```
4. [Install MuJoCo for Gym and/or Robomimic](installation/install_mujoco.md). [Install D3IL](installation/install_d3il.md). [Install IsaacGym and Furniture-Bench](installation/install_furniture.md)
5. Set environment variables for data and logging directory (default is `data/` and `log/`), and set WandB entity (username or team name)
```
source script/set_path.sh
```
## HoReKa Cluster Setup
### Installation on HoReKa
The DPPO repository has been adapted to run on the HoReKa cluster. The original repository recommends conda, but we use vanilla Python with venv.
1. **Clone the repository and navigate to it:**
```bash
git clone git@dominik-roth.eu:dodox/dppo.git
cd dppo
```
Note: This is a fork of the original DPPO repository adapted for HoReKa cluster usage.
2. **Create virtual environment with Python 3.10:**
```bash
python3.10 -m venv .venv
source .venv/bin/activate
```
3. **Install the package and all dependencies:**
```bash
# Submit installation job (runs on dev node with GPU)
sbatch install_dppo.sh
```
Note: Installation must run on a GPU node due to PyTorch CUDA dependencies. The installation script automatically installs ALL environment dependencies (Gym, Robomimic, D3IL).
4. **For fine-tuning: Install and set up MuJoCo 2.1.0**
a) Install MuJoCo 2.1.0 following: https://github.com/openai/mujoco-py#install-mujoco
b) Add these to your `~/.bashrc` or include in SLURM scripts:
```bash
# MuJoCo setup (required for fine-tuning only)
export MUJOCO_PY_MUJOCO_PATH=$HOME/.mujoco/mujoco210
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/.mujoco/mujoco210/bin:/usr/lib/nvidia
export MUJOCO_GL=egl
```
c) **HoReKa Intel Compiler Fix**: Due to Intel OneAPI on HoReKa, mujoco-py compilation fails with Intel compiler flags. The installer provides a comprehensive fix that:
- Creates a GCC wrapper script that filters out Intel-specific compiler flags (`-xCORE-AVX2`, `-xHost`)
- Patches Python's sysconfig and distutils to use GCC instead of Intel compilers
- Downloads missing mujoco-py generated files (`wrappers.pxi`, etc.)
- Pins Cython to version 0.29.37 for compatibility
In your Python scripts that use MuJoCo, import the fix first:
```python
# Apply the fix before importing mujoco_py
exec(open('fix_mujoco_compilation.py').read())
apply_mujoco_fix()
# Then import mujoco_py normally
import mujoco_py
```
This fix is automatically created during installation and resolves all known mujoco-py compilation issues on HoReKa.
### Running on HoReKa
The repository includes pre-configured SLURM scripts for job submission:
#### Quick Start
```bash
# Run a development test (30 minutes, 24GB RAM)
./submit_job.sh dev
# Run Gym pre-training
./submit_job.sh gym hopper pretrain
# Run Gym fine-tuning
./submit_job.sh gym walker2d finetune
```
#### Manual Job Submission
```bash
# Submit development test
sbatch slurm/run_dppo_dev.sh
# Submit Gym experiments with parameters
TASK=hopper MODE=pretrain sbatch slurm/run_dppo_gym.sh
```
#### Supported Tasks
**Gym environments:**
- `hopper`, `walker2d`, `halfcheetah`
**Modes:**
- `pretrain` - Pre-train diffusion policy
- `finetune` - Fine-tune with PPO
#### Resource Allocations
- **Development**: 30 minutes, 24GB RAM, 8 CPUs, dev_accelerated partition
- **Production**: 8 hours, 32GB RAM, 40 CPUs, accelerated partition
#### Monitoring Jobs
```bash
# Check job status
squeue -u $USER
# View logs
tail -f logs/dppo_.out
```
### Configuration
**Required for WandB logging**: Set your credentials as environment variables before submitting jobs:
```bash
# Set these in your shell before running experiments
export WANDB_API_KEY=
export DPPO_WANDB_ENTITY=
# Then submit jobs normally
./submit_job.sh dev
```
**Alternative**: Modify the SLURM scripts directly to set your credentials:
- Edit `slurm/run_dppo_dev.sh` and replace `"your_wandb_username"` with your actual WandB username
- Uncomment and set `WANDB_API_KEY` in the scripts
**Disable WandB**: Add `wandb=null` to python commands if you don't want logging.
### Repository Changes
This fork includes the following additions for HoReKa compatibility:
- `install_dppo.sh` - Automated installation script for SLURM
- `submit_job.sh` - Convenient job submission wrapper
- `slurm/` directory with job scripts for different experiment types
- `EXPERIMENT_PLAN.md` - Comprehensive experiment tracking and validation plan
- Updated `.gitignore` to allow shell scripts (removed `*.sh` exclusion)
- WandB project names prefixed with "dppo-" for better organization
## HoReKa Compatibility Fixes
### Required Environment Setup
```bash
# MuJoCo compilation requirements
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
export CC=gcc
export CXX=g++
# WandB configuration
export DPPO_WANDB_ENTITY="your_wandb_username"
export WANDB_API_KEY="your_api_key"
```
### Configuration Changes Made
- **Python Version**: Uses Python 3.10 instead of original conda Python 3.8
- **WandB Project Names**: Updated to use "dppo-" prefix for better organization
- **Compiler**: Forces GCC due to Intel compiler strictness with MuJoCo
### Current Status
- **Working**: Pre-training for ALL environments (Gym, Robomimic, D3IL) with automatic data download
- **Fixed**: Fine-tuning works with proper MuJoCo environment variables
- **Validated**: Gym fine-tuning functional after fixing parameter names and environment setup
- **Not Compatible**: Furniture-Bench requires Python 3.8 (incompatible with our Python 3.10 setup)
### How to Use This Repository on HoReKa
1. **Check experiment status**: See `EXPERIMENT_PLAN.md` for current validation progress and todo list
2. **Run development tests**: Use `TASK= MODE= sbatch slurm/run_dppo_dev_flexible.sh`
3. **Monitor jobs**: `squeue -u $USER` and check logs in `logs/` directory
4. **View results**: WandB projects will appear under `dppo---` naming
5. **Scale to production**: Only after all dev validations pass (see Phase 2 in experiment plan)
## Usage - Pre-training
**Note**: You may skip pre-training if you would like to use the default checkpoint (available for download) for fine-tuning.
Pre-training data for all tasks are pre-processed and can be found at [here](https://drive.google.com/drive/folders/1AXZvNQEKOrp0_jk1VLepKh_oHCg_9e3r?usp=drive_link). Pre-training script will download the data (including normalization statistics) automatically to the data directory.
### Run pre-training with data
All the configs can be found under `cfg//pretrain/`. A new WandB project may be created based on `wandb.project` in the config file; set `wandb=null` in the command line to test without WandB logging.
```console
# Gym - hopper/walker2d/halfcheetah
python script/run.py --config-name=pre_diffusion_mlp \
--config-dir=cfg/gym/pretrain/hopper-medium-v2
# Robomimic - lift/can/square/transport
python script/run.py --config-name=pre_diffusion_mlp \
--config-dir=cfg/robomimic/pretrain/can
# D3IL - avoid_m1/m2/m3
python script/run.py --config-name=pre_diffusion_mlp \
--config-dir=cfg/d3il/pretrain/avoid_m1
# Furniture-Bench - one_leg/lamp/round_table_low/med
python script/run.py --config-name=pre_diffusion_mlp \
--config-dir=cfg/furniture/pretrain/one_leg_low
```
See [here](cfg/pretraining.md) for details of the experiments in the paper.
## Usage - Fine-tuning
Pre-trained policies used in the paper can be found [here](https://drive.google.com/drive/folders/1ZlFqmhxC4S8Xh1pzZ-fXYzS5-P8sfpiP?usp=drive_link). Fine-tuning script will download the default checkpoint automatically to the logging directory.
### Fine-tuning pre-trained policy
All the configs can be found under `cfg//finetune/`. A new WandB project may be created based on `wandb.project` in the config file; set `wandb=null` in the command line to test without WandB logging.
```console
# Gym - hopper/walker2d/halfcheetah
python script/run.py --config-name=ft_ppo_diffusion_mlp \
--config-dir=cfg/gym/finetune/hopper-v2
# Robomimic - lift/can/square/transport
python script/run.py --config-name=ft_ppo_diffusion_mlp \
--config-dir=cfg/robomimic/finetune/can
# D3IL - avoid_m1/m2/m3
python script/run.py --config-name=ft_ppo_diffusion_mlp \
--config-dir=cfg/d3il/finetune/avoid_m1
# Furniture-Bench - one_leg/lamp/round_table_low/med
python script/run.py --config-name=ft_ppo_diffusion_mlp \
--config-dir=cfg/furniture/finetune/one_leg_low
```
**Note**: In Gym, Robomimic, and D3IL tasks, we run 40, 50, and 50 parallelized MuJoCo environments on CPU, respectively. If you would like to use fewer environments (given limited CPU threads, or GPU memory for rendering), you can reduce `env.n_envs` and increase `train.n_steps`, so the total number of environment steps collected in each iteration (n_envs x n_steps x act_steps) remains roughly the same. Try to set `train.n_steps` a multiple of `env.max_episode_steps / act_steps`, and be aware that we only count episodes finished within an iteration for eval. Furniture-Bench tasks run IsaacGym on a single GPU.
To fine-tune your own pre-trained policy instead, override `base_policy_path` to your own checkpoint, which is saved under `checkpoint/` of the pre-training directory. You can set `base_policy_path=` in the command line when launching fine-tuning.
See [here](cfg/finetuning.md) for details of the experiments in the paper.
### Visualization
* Furniture-Bench tasks can be visualized in GUI by specifying `env.specific.headless=False` and `env.n_envs=1` in fine-tuning configs.
* D3IL environment can be visualized in GUI by `+env.render=True`, `env.n_envs=1`, and `train.render.num=1`. There is a basic script at `script/test_d3il_render.py`.
* Videos of trials in Robomimic tasks can be recorded by specifying `env.save_video=True`, `train.render.freq=`, and `train.render.num=` in fine-tuning configs.
## Usage - Evaluation
Pre-trained or fine-tuned policies can be evaluated without running the fine-tuning script now. Some example configs are provided under `cfg/{gym/robomimic/furniture}/eval}` including ones below. Set `base_policy_path` to override the default checkpoint, and `ft_denoising_steps` needs to match fine-tuning config (otherwise assumes `ft_denoising_steps=0`, which means evaluating the pre-trained policy).
```console
python script/run.py --config-name=eval_diffusion_mlp \
--config-dir=cfg/gym/eval/hopper-v2 ft_denoising_steps=?
python script/run.py --config-name=eval_{diffusion/gaussian}_mlp_{?img} \
--config-dir=cfg/robomimic/eval/can ft_denoising_steps=?
python script/run.py --config-name=eval_diffusion_mlp \
--config-dir=cfg/furniture/eval/one_leg_low ft_denoising_steps=?
```
## DPPO implementation
Our diffusion implementation is mostly based on [Diffuser](https://github.com/jannerm/diffuser) and at [`model/diffusion/diffusion.py`](model/diffusion/diffusion.py) and [`model/diffusion/diffusion_vpg.py`](model/diffusion/diffusion_vpg.py). PPO specifics are implemented at [`model/diffusion/diffusion_ppo.py`](model/diffusion/diffusion_ppo.py). The main training script is at [`agent/finetune/train_ppo_diffusion_agent.py`](agent/finetune/train_ppo_diffusion_agent.py) that follows [CleanRL](https://github.com/vwxyzjn/cleanrl).
### Key configurations
* `denoising_steps`: number of denoising steps (should always be the same for pre-training and fine-tuning regardless the fine-tuning scheme)
* `ft_denoising_steps`: number of fine-tuned denoising steps
* `horizon_steps`: predicted action chunk size (should be the same as `act_steps`, executed action chunk size, with MLP. Can be different with UNet, e.g., `horizon_steps=16` and `act_steps=8`)
* `model.gamma_denoising`: denoising discount factor
* `model.min_sampling_denoising_std`:
> DPPO is an algorithmic framework and set of best practices for fine-tuning diffusion-based policies in continuous control and robot learning tasks.
## Installation
1. Clone the repository
```console
git clone git@github.com:irom-lab/dppo.git
cd dppo
```
2. Install core dependencies with a conda environment (if you do not plan to use Furniture-Bench, a higher Python version such as 3.10 can be installed instead) on a Linux machine with a Nvidia GPU.
```console
conda create -n dppo python=3.8 -y
conda activate dppo
pip install -e .
```
3. Install specific environment dependencies (Gym / Kitchen / Robomimic / D3IL / Furniture-Bench) or all dependencies (except for Kitchen, which has dependency conflicts with other tasks).
```console
pip install -e .[gym] # or [kitchen], [robomimic], [d3il], [furniture]
pip install -e .[all] # except for Kitchen
```
4. [Install MuJoCo for Gym and/or Robomimic](installation/install_mujoco.md). [Install D3IL](installation/install_d3il.md). [Install IsaacGym and Furniture-Bench](installation/install_furniture.md)
5. Set environment variables for data and logging directory (default is `data/` and `log/`), and set WandB entity (username or team name)
```
source script/set_path.sh
```
## HoReKa Cluster Setup
### Installation on HoReKa
The DPPO repository has been adapted to run on the HoReKa cluster. The original repository recommends conda, but we use vanilla Python with venv.
1. **Clone the repository and navigate to it:**
```bash
git clone git@dominik-roth.eu:dodox/dppo.git
cd dppo
```
Note: This is a fork of the original DPPO repository adapted for HoReKa cluster usage.
2. **Create virtual environment with Python 3.10:**
```bash
python3.10 -m venv .venv
source .venv/bin/activate
```
3. **Install the package and all dependencies:**
```bash
# Submit installation job (runs on dev node with GPU)
sbatch install_dppo.sh
```
Note: Installation must run on a GPU node due to PyTorch CUDA dependencies. The installation script automatically installs ALL environment dependencies (Gym, Robomimic, D3IL).
4. **For fine-tuning: Install and set up MuJoCo 2.1.0**
a) Install MuJoCo 2.1.0 following: https://github.com/openai/mujoco-py#install-mujoco
b) Add these to your `~/.bashrc` or include in SLURM scripts:
```bash
# MuJoCo setup (required for fine-tuning only)
export MUJOCO_PY_MUJOCO_PATH=$HOME/.mujoco/mujoco210
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/.mujoco/mujoco210/bin:/usr/lib/nvidia
export MUJOCO_GL=egl
```
c) **HoReKa Intel Compiler Fix**: Due to Intel OneAPI on HoReKa, mujoco-py compilation fails with Intel compiler flags. The installer provides a comprehensive fix that:
- Creates a GCC wrapper script that filters out Intel-specific compiler flags (`-xCORE-AVX2`, `-xHost`)
- Patches Python's sysconfig and distutils to use GCC instead of Intel compilers
- Downloads missing mujoco-py generated files (`wrappers.pxi`, etc.)
- Pins Cython to version 0.29.37 for compatibility
In your Python scripts that use MuJoCo, import the fix first:
```python
# Apply the fix before importing mujoco_py
exec(open('fix_mujoco_compilation.py').read())
apply_mujoco_fix()
# Then import mujoco_py normally
import mujoco_py
```
This fix is automatically created during installation and resolves all known mujoco-py compilation issues on HoReKa.
### Running on HoReKa
The repository includes pre-configured SLURM scripts for job submission:
#### Quick Start
```bash
# Run a development test (30 minutes, 24GB RAM)
./submit_job.sh dev
# Run Gym pre-training
./submit_job.sh gym hopper pretrain
# Run Gym fine-tuning
./submit_job.sh gym walker2d finetune
```
#### Manual Job Submission
```bash
# Submit development test
sbatch slurm/run_dppo_dev.sh
# Submit Gym experiments with parameters
TASK=hopper MODE=pretrain sbatch slurm/run_dppo_gym.sh
```
#### Supported Tasks
**Gym environments:**
- `hopper`, `walker2d`, `halfcheetah`
**Modes:**
- `pretrain` - Pre-train diffusion policy
- `finetune` - Fine-tune with PPO
#### Resource Allocations
- **Development**: 30 minutes, 24GB RAM, 8 CPUs, dev_accelerated partition
- **Production**: 8 hours, 32GB RAM, 40 CPUs, accelerated partition
#### Monitoring Jobs
```bash
# Check job status
squeue -u $USER
# View logs
tail -f logs/dppo_.out
```
### Configuration
**Required for WandB logging**: Set your credentials as environment variables before submitting jobs:
```bash
# Set these in your shell before running experiments
export WANDB_API_KEY=
export DPPO_WANDB_ENTITY=
# Then submit jobs normally
./submit_job.sh dev
```
**Alternative**: Modify the SLURM scripts directly to set your credentials:
- Edit `slurm/run_dppo_dev.sh` and replace `"your_wandb_username"` with your actual WandB username
- Uncomment and set `WANDB_API_KEY` in the scripts
**Disable WandB**: Add `wandb=null` to python commands if you don't want logging.
### Repository Changes
This fork includes the following additions for HoReKa compatibility:
- `install_dppo.sh` - Automated installation script for SLURM
- `submit_job.sh` - Convenient job submission wrapper
- `slurm/` directory with job scripts for different experiment types
- `EXPERIMENT_PLAN.md` - Comprehensive experiment tracking and validation plan
- Updated `.gitignore` to allow shell scripts (removed `*.sh` exclusion)
- WandB project names prefixed with "dppo-" for better organization
## HoReKa Compatibility Fixes
### Required Environment Setup
```bash
# MuJoCo compilation requirements
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
export CC=gcc
export CXX=g++
# WandB configuration
export DPPO_WANDB_ENTITY="your_wandb_username"
export WANDB_API_KEY="your_api_key"
```
### Configuration Changes Made
- **Python Version**: Uses Python 3.10 instead of original conda Python 3.8
- **WandB Project Names**: Updated to use "dppo-" prefix for better organization
- **Compiler**: Forces GCC due to Intel compiler strictness with MuJoCo
### Current Status
- **Working**: Pre-training for ALL environments (Gym, Robomimic, D3IL) with automatic data download
- **Fixed**: Fine-tuning works with proper MuJoCo environment variables
- **Validated**: Gym fine-tuning functional after fixing parameter names and environment setup
- **Not Compatible**: Furniture-Bench requires Python 3.8 (incompatible with our Python 3.10 setup)
### How to Use This Repository on HoReKa
1. **Check experiment status**: See `EXPERIMENT_PLAN.md` for current validation progress and todo list
2. **Run development tests**: Use `TASK= MODE= sbatch slurm/run_dppo_dev_flexible.sh`
3. **Monitor jobs**: `squeue -u $USER` and check logs in `logs/` directory
4. **View results**: WandB projects will appear under `dppo---` naming
5. **Scale to production**: Only after all dev validations pass (see Phase 2 in experiment plan)
## Usage - Pre-training
**Note**: You may skip pre-training if you would like to use the default checkpoint (available for download) for fine-tuning.
Pre-training data for all tasks are pre-processed and can be found at [here](https://drive.google.com/drive/folders/1AXZvNQEKOrp0_jk1VLepKh_oHCg_9e3r?usp=drive_link). Pre-training script will download the data (including normalization statistics) automatically to the data directory.
### Run pre-training with data
All the configs can be found under `cfg//pretrain/`. A new WandB project may be created based on `wandb.project` in the config file; set `wandb=null` in the command line to test without WandB logging.
```console
# Gym - hopper/walker2d/halfcheetah
python script/run.py --config-name=pre_diffusion_mlp \
--config-dir=cfg/gym/pretrain/hopper-medium-v2
# Robomimic - lift/can/square/transport
python script/run.py --config-name=pre_diffusion_mlp \
--config-dir=cfg/robomimic/pretrain/can
# D3IL - avoid_m1/m2/m3
python script/run.py --config-name=pre_diffusion_mlp \
--config-dir=cfg/d3il/pretrain/avoid_m1
# Furniture-Bench - one_leg/lamp/round_table_low/med
python script/run.py --config-name=pre_diffusion_mlp \
--config-dir=cfg/furniture/pretrain/one_leg_low
```
See [here](cfg/pretraining.md) for details of the experiments in the paper.
## Usage - Fine-tuning
Pre-trained policies used in the paper can be found [here](https://drive.google.com/drive/folders/1ZlFqmhxC4S8Xh1pzZ-fXYzS5-P8sfpiP?usp=drive_link). Fine-tuning script will download the default checkpoint automatically to the logging directory.
### Fine-tuning pre-trained policy
All the configs can be found under `cfg//finetune/`. A new WandB project may be created based on `wandb.project` in the config file; set `wandb=null` in the command line to test without WandB logging.
```console
# Gym - hopper/walker2d/halfcheetah
python script/run.py --config-name=ft_ppo_diffusion_mlp \
--config-dir=cfg/gym/finetune/hopper-v2
# Robomimic - lift/can/square/transport
python script/run.py --config-name=ft_ppo_diffusion_mlp \
--config-dir=cfg/robomimic/finetune/can
# D3IL - avoid_m1/m2/m3
python script/run.py --config-name=ft_ppo_diffusion_mlp \
--config-dir=cfg/d3il/finetune/avoid_m1
# Furniture-Bench - one_leg/lamp/round_table_low/med
python script/run.py --config-name=ft_ppo_diffusion_mlp \
--config-dir=cfg/furniture/finetune/one_leg_low
```
**Note**: In Gym, Robomimic, and D3IL tasks, we run 40, 50, and 50 parallelized MuJoCo environments on CPU, respectively. If you would like to use fewer environments (given limited CPU threads, or GPU memory for rendering), you can reduce `env.n_envs` and increase `train.n_steps`, so the total number of environment steps collected in each iteration (n_envs x n_steps x act_steps) remains roughly the same. Try to set `train.n_steps` a multiple of `env.max_episode_steps / act_steps`, and be aware that we only count episodes finished within an iteration for eval. Furniture-Bench tasks run IsaacGym on a single GPU.
To fine-tune your own pre-trained policy instead, override `base_policy_path` to your own checkpoint, which is saved under `checkpoint/` of the pre-training directory. You can set `base_policy_path=` in the command line when launching fine-tuning.
See [here](cfg/finetuning.md) for details of the experiments in the paper.
### Visualization
* Furniture-Bench tasks can be visualized in GUI by specifying `env.specific.headless=False` and `env.n_envs=1` in fine-tuning configs.
* D3IL environment can be visualized in GUI by `+env.render=True`, `env.n_envs=1`, and `train.render.num=1`. There is a basic script at `script/test_d3il_render.py`.
* Videos of trials in Robomimic tasks can be recorded by specifying `env.save_video=True`, `train.render.freq=`, and `train.render.num=` in fine-tuning configs.
## Usage - Evaluation
Pre-trained or fine-tuned policies can be evaluated without running the fine-tuning script now. Some example configs are provided under `cfg/{gym/robomimic/furniture}/eval}` including ones below. Set `base_policy_path` to override the default checkpoint, and `ft_denoising_steps` needs to match fine-tuning config (otherwise assumes `ft_denoising_steps=0`, which means evaluating the pre-trained policy).
```console
python script/run.py --config-name=eval_diffusion_mlp \
--config-dir=cfg/gym/eval/hopper-v2 ft_denoising_steps=?
python script/run.py --config-name=eval_{diffusion/gaussian}_mlp_{?img} \
--config-dir=cfg/robomimic/eval/can ft_denoising_steps=?
python script/run.py --config-name=eval_diffusion_mlp \
--config-dir=cfg/furniture/eval/one_leg_low ft_denoising_steps=?
```
## DPPO implementation
Our diffusion implementation is mostly based on [Diffuser](https://github.com/jannerm/diffuser) and at [`model/diffusion/diffusion.py`](model/diffusion/diffusion.py) and [`model/diffusion/diffusion_vpg.py`](model/diffusion/diffusion_vpg.py). PPO specifics are implemented at [`model/diffusion/diffusion_ppo.py`](model/diffusion/diffusion_ppo.py). The main training script is at [`agent/finetune/train_ppo_diffusion_agent.py`](agent/finetune/train_ppo_diffusion_agent.py) that follows [CleanRL](https://github.com/vwxyzjn/cleanrl).
### Key configurations
* `denoising_steps`: number of denoising steps (should always be the same for pre-training and fine-tuning regardless the fine-tuning scheme)
* `ft_denoising_steps`: number of fine-tuned denoising steps
* `horizon_steps`: predicted action chunk size (should be the same as `act_steps`, executed action chunk size, with MLP. Can be different with UNet, e.g., `horizon_steps=16` and `act_steps=8`)
* `model.gamma_denoising`: denoising discount factor
* `model.min_sampling_denoising_std`:  , minimum amount of noise when sampling at a denoising step
* `model.min_logprob_denoising_std`:
, minimum amount of noise when sampling at a denoising step
* `model.min_logprob_denoising_std`:  , minimum standard deviation when evaluating likelihood at a denoising step
* `model.clip_ploss_coef`: PPO clipping ratio
* `train.batch_size`: you may notice the batch size is rather large --- this is due to the PPO update being in expectation over both environment steps and denoising steps (new in v0.6).
### DDIM fine-tuning
To use DDIM fine-tuning, set `denoising_steps=100` in pre-training and set `model.use_ddim=True`, `model.ddim_steps` to the desired number of total DDIM steps, and `ft_denoising_steps` to the desired number of fine-tuned DDIM steps. In our Furniture-Bench experiments we use `denoising_steps=100`, `model.ddim_steps=5`, and `ft_denoising_steps=5`.
## Adding your own dataset/environment
### Pre-training data
Pre-training script is at [`agent/pretrain/train_diffusion_agent.py`](agent/pretrain/train_diffusion_agent.py). The pre-training dataset [loader](agent/dataset/sequence.py) assumes a npz file containing numpy arrays `states`, `actions`, `images` (if using pixel; img_h = img_w and a multiple of 8) and `traj_lengths`, where `states` and `actions` have the shape of num_total_steps x obs_dim/act_dim, `images` num_total_steps x C (concatenated if multiple images) x H x W, and `traj_lengths` is a 1-D array for indexing across num_total_steps.
#### Observation history
In our experiments we did not use any observation from previous timesteps (state or pixel), but it is implemented. You can set `cond_steps=` (and `img_cond_steps=`, no larger than `cond_steps`) in pre-training, and set the same when fine-tuning the newly pre-trained policy.
### Fine-tuning environment
We follow the Gym format for interacting with the environments. The vectorized environments are initialized at [make_async](env/gym_utils/__init__.py#L10) (called in the parent fine-tuning agent class [here](agent/finetune/train_agent.py#L38-L39)). The current implementation is not the cleanest as we tried to make it compatible with Gym, Robomimic, Furniture-Bench, and D3IL environments, but it should be easy to modify and allow using other environments. We use [multi_step](env/gym_utils/wrapper/multi_step.py) wrapper for history observations and multi-environment-step action execution. We also use environment-specific wrappers such as [robomimic_lowdim](env/gym_utils/wrapper/robomimic_lowdim.py) and [furniture](env/gym_utils/wrapper/furniture.py) for observation/action normalization, etc. You can implement a new environment wrapper if needed.
## Known issues
* IsaacGym simulation can become unstable at times and lead to NaN observations in Furniture-Bench. The current env wrapper does not handle NaN observations.
## License
This repository is released under the MIT license. See [LICENSE](LICENSE).
## Acknowledgement
* [Diffuser, Janner et al.](https://github.com/jannerm/diffuser): general code base and DDPM implementation
* [Diffusion Policy, Chi et al.](https://github.com/real-stanford/diffusion_policy): general code base especially the env wrappers
* [CleanRL, Huang et al.](https://github.com/vwxyzjn/cleanrl): PPO implementation
* [IBRL, Hu et al.](https://github.com/hengyuan-hu/ibrl): ViT implementation
* [D3IL, Jia et al.](https://github.com/ALRhub/d3il): D3IL benchmark
* [Robomimic, Mandlekar et al.](https://github.com/ARISE-Initiative/robomimic): Robomimic benchmark
* [Furniture-Bench, Heo et al.](https://github.com/clvrai/furniture-bench): Furniture-Bench benchmark
* [AWR, Peng et al.](https://github.com/xbpeng/awr): DAWR baseline (modified from AWR)
* [DIPO, Yang et al.](https://github.com/BellmanTimeHut/DIPO): DIPO baseline
* [IDQL, Hansen-Estruch et al.](https://github.com/philippe-eecs/IDQL): IDQL baseline
* [DQL, Wang et al.](https://github.com/Zhendong-Wang/Diffusion-Policies-for-Offline-RL): DQL baseline
* [QSM, Psenka et al.](https://www.michaelpsenka.io/qsm/): QSM baseline
* [Score SDE, Song et al.](https://github.com/yang-song/score_sde_pytorch/): diffusion exact likelihood
, minimum standard deviation when evaluating likelihood at a denoising step
* `model.clip_ploss_coef`: PPO clipping ratio
* `train.batch_size`: you may notice the batch size is rather large --- this is due to the PPO update being in expectation over both environment steps and denoising steps (new in v0.6).
### DDIM fine-tuning
To use DDIM fine-tuning, set `denoising_steps=100` in pre-training and set `model.use_ddim=True`, `model.ddim_steps` to the desired number of total DDIM steps, and `ft_denoising_steps` to the desired number of fine-tuned DDIM steps. In our Furniture-Bench experiments we use `denoising_steps=100`, `model.ddim_steps=5`, and `ft_denoising_steps=5`.
## Adding your own dataset/environment
### Pre-training data
Pre-training script is at [`agent/pretrain/train_diffusion_agent.py`](agent/pretrain/train_diffusion_agent.py). The pre-training dataset [loader](agent/dataset/sequence.py) assumes a npz file containing numpy arrays `states`, `actions`, `images` (if using pixel; img_h = img_w and a multiple of 8) and `traj_lengths`, where `states` and `actions` have the shape of num_total_steps x obs_dim/act_dim, `images` num_total_steps x C (concatenated if multiple images) x H x W, and `traj_lengths` is a 1-D array for indexing across num_total_steps.
#### Observation history
In our experiments we did not use any observation from previous timesteps (state or pixel), but it is implemented. You can set `cond_steps=` (and `img_cond_steps=`, no larger than `cond_steps`) in pre-training, and set the same when fine-tuning the newly pre-trained policy.
### Fine-tuning environment
We follow the Gym format for interacting with the environments. The vectorized environments are initialized at [make_async](env/gym_utils/__init__.py#L10) (called in the parent fine-tuning agent class [here](agent/finetune/train_agent.py#L38-L39)). The current implementation is not the cleanest as we tried to make it compatible with Gym, Robomimic, Furniture-Bench, and D3IL environments, but it should be easy to modify and allow using other environments. We use [multi_step](env/gym_utils/wrapper/multi_step.py) wrapper for history observations and multi-environment-step action execution. We also use environment-specific wrappers such as [robomimic_lowdim](env/gym_utils/wrapper/robomimic_lowdim.py) and [furniture](env/gym_utils/wrapper/furniture.py) for observation/action normalization, etc. You can implement a new environment wrapper if needed.
## Known issues
* IsaacGym simulation can become unstable at times and lead to NaN observations in Furniture-Bench. The current env wrapper does not handle NaN observations.
## License
This repository is released under the MIT license. See [LICENSE](LICENSE).
## Acknowledgement
* [Diffuser, Janner et al.](https://github.com/jannerm/diffuser): general code base and DDPM implementation
* [Diffusion Policy, Chi et al.](https://github.com/real-stanford/diffusion_policy): general code base especially the env wrappers
* [CleanRL, Huang et al.](https://github.com/vwxyzjn/cleanrl): PPO implementation
* [IBRL, Hu et al.](https://github.com/hengyuan-hu/ibrl): ViT implementation
* [D3IL, Jia et al.](https://github.com/ALRhub/d3il): D3IL benchmark
* [Robomimic, Mandlekar et al.](https://github.com/ARISE-Initiative/robomimic): Robomimic benchmark
* [Furniture-Bench, Heo et al.](https://github.com/clvrai/furniture-bench): Furniture-Bench benchmark
* [AWR, Peng et al.](https://github.com/xbpeng/awr): DAWR baseline (modified from AWR)
* [DIPO, Yang et al.](https://github.com/BellmanTimeHut/DIPO): DIPO baseline
* [IDQL, Hansen-Estruch et al.](https://github.com/philippe-eecs/IDQL): IDQL baseline
* [DQL, Wang et al.](https://github.com/Zhendong-Wang/Diffusion-Policies-for-Offline-RL): DQL baseline
* [QSM, Psenka et al.](https://www.michaelpsenka.io/qsm/): QSM baseline
* [Score SDE, Song et al.](https://github.com/yang-song/score_sde_pytorch/): diffusion exact likelihood